Chapter 10 - Transformers
Transformers are the latest step in the evolution of deep learning. As is necessary with progress, newer deep learning algorithms are also much more complicated, with deeper and more resource intensive networks. The Transformer is the best example of this. Transformers are, for me, the first algorithm I was not able to run on a laptop when using a significantly large data set. They truly require a machine learning “war machine”. Lots of GPU power and memory, etc. The algorithms are much more complicated, as you will see, and the networks are very deep. Transformers are one of the new innovations in NLP since 2017. They were first made popular by the paper “Attention Is All You Need” by (Vaswani et al.). They are very interesting and seem to be very powerful. Currently, they are better than Recurrent Neural Networks (RNNs) for NLP because they parallelize better and because of the Attention mechanism. So far, Transformers have been used to develop very impressive implementations such as BERT (Devlin et al. 2018), and GPT-3 (Radford et al. 2019), and most notably, chatGPT from OpenAI, as of this writing. ChatGPT in particular seems to be very good at language understanding. Transformers have also been applied to language translation, question answering, document summarization, automatic code generation, text generation, etc. In general, something like chatGPT requires at least 2 steps. One step is called the Pre-Training process and the other step is called fine tuning. Basically, a Transformer network is trained on all the data you have (e.g. all text data in the world). This process requires massive amounts of computing and can be very expensive. The most notable pre-trained GPTs include: GPT-3, GPT-4, and LlaMa models, to name a few. The next step is to fine tune the model. Once the fine tuning is complete, you have options such as adding more neural net layers after the transformer and freezing the already pre-trained weights. Or you can just keep training the transformer for a specific task and have all the weights be changed. The amount of fine tuning data does not need to be as large as the data for pre-training. In fact, it can be orders of magnitude smaller. Okay, let’s get started.
Copyright and License
All rights reserved. No part of this work may be reproduced or transmitted in any form or by any means, without written permission of the copyright owner.
MIT License.
FTC and Amazon Disclaimer
This post/page/article includes Amazon Affiliate links to products. This site receives income if you purchase through these links.
This income helps support content such as this one.

Main Ideas of the Transformer
So, where does one start with Transformers? The Transformer is complex and it involves several ideas to make it work correctly. In this section I will present the main ideas first with some relevant code. Understanding these concepts or steps really well before venturing to write the code for the Transformers is really important. It will save you time in the long run. So now, let us proceed to discuss these topics. In the next sections I will start discussing the code for GPTs, BERTs, the full Encoder Decoder transformer architecture, and a few other subjects. As can be seen in the previous figure, the original Transformer consisted of an Encoder and a Decoder layer.
Numpy arrays, tensors, and linear algebra
Linear algebra, numpy arrays, and tensor operations are at the heart of understanding the Transformer architecture. Before you continue, I strongly recommend that you read and practice the topics in chapter 1, and in particular, the section on linear algebra, numpy arrays, and tensor operations.
Attention
The Attention mechanism in Transformers is the heart of the whole algorithm. The attention matrix is nothing more than a dot product matrix multiplication between all the tokens (e.g. words, syllables, subwords, etc.) in a sentence (e.g. the input English sentence). The idea is that, given the input and output, the model learns to correlate the words in the sentence to determine their importance. This is done multiple times and that is why it is called a multi head attention mechanism.
Embeddings
Sequences of tokens in a sentence are converted into sequences of IDs. An Embedding approach converts the sequence of ids into a sequence of embeddings. You will go from a 2d tensor
[N_batches, _tokens]
to a 3d tensor of size:
[N_batches, N_tokens , embedding_dimension ]
The term N_tokens can also be called seq_length_max. Here N_batches is the batch size, N_tokens or seq_length_max is 40, and embedding_dimension is 512.
The term N_tokens (i.e. 40) just establishes the size of the input sentences we wiil allow. Sentences in Transformers are not of variable length. Instead you define
a buffer size to hold the sentence. If the sentence is too long, then it is truncated. If the sentence is too short, then the buffer is padded. The embedding size is
selected arbitrarily like in word2vec.
Masks
Masks serve several purposes. One is to help ignore the padded values during training. The other goal is to block the given word you want to predict or future words). This brings up the important aspect of training with Transformers. Transformers predict the last word in a sequence. For example:
Given an input in english: "the cat is sleeping"
a Transformer is also given part of the output sentence. In this case: "el gato esta ?". The Transformer will predict the next word in the sequence which in this case would be "durmiendo" to complete the translation as “el gato esta durmiendo”. All of this is achieved through the masks to ignore padded values and to only show the partial sentence.
Positional Encoding
This is the technique that allows you to encode sequence. Transformers are all about being parallel. Their direct competitor is Recurrent Neural Networks (RNNs). RNNs have had several problems in the past. One is that they do not scale well to GPUs and parallel approaches because of their recurrence and dependence on previous steps. The other problem is the famous "vanishing gradients" problem which was addressed by by residuals and LSTMs seem to have addressed this now. Transformers did away with the type of sequence modeling approach used in RNNs all together so they are very good for parallel approaches. But how do they address or encode the sequence? Obviously knowing that the word "cat" goes before the word "sleeping" is useful. This is where a technique called positional encoding comes into play. Basically, after embedding, you have a vector per token of, say, size 512. Now, with positional encoding, a function that calculates sines and cosines, is used to create a new vector also of size 512 that represents position (i.e. sequence) of the tokens. The 2 vectors are added together (embedding + positional_encoding) to get the new inputs to the network. Also, the position vector values are smaller than the embedding vector values so as to not let position dominate.
Tokens
In a GPT we want to predict the next word given previous words. However, to improve performance, transformer models do not predict the next word. Instead, they
predict the next subword. A good analogy for subword is syllable, although transformer do not use syllables either. The subwords are calculated based on specific
algorithm such as BPE or SentencePiece. This allows transformers to learn to generate new words never seen before. For example, it may have seen
The dog is play - ing.
And by breaking the word into subwords (i.e. play and ing), it can learn to generate new variations of words it never saw before such as
The lady is iphone - ing.
We and the Transformer know intuitively what this means.
The fact is that tokens can be words, syllables, subwords, letters, etc. Subwords through SentencePiece type algorithms just have proven to give the best results.
Inputs and Outputs
So, let us start there. Let's quickly remember our classic example of MNIST supervised classification. In MNIST standard feed forward classification, you have an
input image which is 28x28 and a predicted vector of size 10 for the classes. So, what do the inputs and outputs look like for transformers? For language translation,
they are lists of ids. Each id can represent a word in a sentence. This is best visualized with an example.
First, let us look at the classic use case for Transformers. As I said earlier, Transformers have been used extensibly in NLP. And the first example was in language
translation where we have sentence pairs. Such as the following for English-Spanish translation:
"the cat is sleeping" --> which translates to -- > "el gato esta durmiendo"
Therefore, first we need to understand how to encode this for the neural network and then to understand how exactly it is that the network will train and learn.
So, again, before you look into the network's very deep and complex layers, I believe that one needs to focus on:
- Padding these sequences of ids
- Taking text sentences and converting them into sequences of ids
Consider that after encoding and padding, your sentences will look like this:
and for the other language
GPTs
GPTs stand for Generative Pre-trained Transformers. The GPT uses the decoder only part of the Transformer. The input to the decoder varies based on whether you are
training or predicting. If you are training, the input to the decoder is the sentence itself. When training, a mask is needed here to prevent the model from
seeing all the words it is trying to predict. This is called a look ahead mask.
If you are testing, the input is just the previous words before the word you are trying to predict. You start with a start of sentence token (e.g.
Each decoder layer consists of a decoder multi-head attention layer, followed by a fully connected layer. The attention layers consist of m_heads (e.g. 8) parallel attention sub layers that are later concatenated. The numbers 6 and 8 are a choice the architect makes.
Teacher Forcing
You may have already read somewhere (on-line) that the Decoder in the Transformer network predicts one word at a time and that that word is read back as an input in the next iteration. Also, the network predicts the last word in the sequence of words. But you may think, aren't those last words just padding? Eh? So, what is going on here? As it turns out, the mechanism of predicting one word at a time and feeding it back as an input in the next iteration is only done during the "testing" phase and it is not done during "training". Instead, during "training" of a decoder we use “Teacher Forcing”. Teacher forcing is a technique in auto regressive models where you do not use the predicted outputs of the decoder to feed back as input but instead you use the real data. This helps the model to learn the correct information instead of its own erroneous predictions (especially at the beginning of training).
Implementing a GPT in PyTorch from Scratch
In this section, I will implement a simple GPT using everything we have learned in this book. The code will be very object oriented for efficiency. That being said,
this GPT is implemented from scratch, works really well, and can be scaled. Thanks to Andrej Karpathy for helping me to better understand the PyTorch
implementation of a GPT (Andrej Karpathy). There are many implementations of GPTs out there. The GPT discussed in this
section is based on Andrej Karpathy's GPT implementation. I have modified it a bit to be consistent with the original Vaswani paper (Attention is all you need).
For the sake of simplicity I will not use subwords here and instead just use the letters of the English alphabet and a few symbols. The vocabulary of a large GPT such as
GPT-4 could be hundreds of thousands of subwords or more. This GPT reads in one text file and trains on it.
Here, we first input our common python libraries.
In the following code segment we can set the parameters as we have done before.
Now we proceed to read the text data to train on.
After reading the text file, we can look at the information about it with the following code.
With the previous code we can look at the length of the text and type of characters. The length of data in letters or characters is 2,365,132, for instance. The characters can be seen in the next code listing.
With the following code we can calculate the size of the vocabulary which is 65 and can print the tokens as a string.
The tokens need to be converted into IDs. We can use a dictionary and reverse dictionary for this like so. This was previously shown in the word2vec code description. These are called the tokenizer.
We can now print the dictionary (string to int ) and reverse dictionary (int to string).
The string to int dictionary will give us
and the int to string dictionary will give us
Now we need to define an encoding tokenizer called "encode" so we can convert string to integer.
Encoding from the sheep language "bahh" with the tokenizer encoder gives [40, 39, 46, 46].
We do the same for the tokenizer decode to decoder from integer to strings as follows:
Using the function decode([40, 39, 46, 46]) gives us our sheep tokens back which are 'bahh'. Now we need to encode the text from our book and convert it to a Torch tensor. The code for that is as follows:
Printing the encoded data in the Torch tensor gives us:
tensor([18, 47, 56, ..., 45, 8, 0])
We now proceed to split the data into train and text. We do that next by slicing the data torch tensor with $ n $.
The next step is to create a function to read the data so we can train the GPT. We will use a function to get the data in batches. The code can be seen in the next code listing.
To better understand the previous function, I will create a simple example with smaller values for the batch size and the M\_tokens parameter.
This will help to illustrate what is going on on this function.
A GPT is a very deep neural network. To train it you need inputs ( "x" ) and outputs ( "y" ). Inputs and outputs are matrices of the
same size [batch_size, N_tokens]. They are basically several sentences as rows (batch_size) with N_tokens (i.e. 40) as columns for each sentence.
The same sentence is selected for "x" and "y" . They are the same sentence but "y" is shifted by one from "x".
For our example, we can slice batches of 4 with a sentence sequence length of 16. The torch.randint function helps us to select random starting points for the 4 sentences
from the text. Printing the variable "ix" from the code below gives us the following 4 starting points in the text.
tensor([ 213173, 989153, 193174, 874116 ])
Given the four index position (13173, 989153, 193174, 874116), we can see what Tokenizer IDs are stored there with the following code listing. The "for" loop gives us:
tensor(59), tensor(43), tensor(58), tensor(17)
Now with these 4 index positions we can proceed to slice out the four sentences of size 16 from the torch data tensor. Remember that we hold IDs for the tokens and not the actual letter in this tensor. This gives us 4 pairs of (x, y). Notice that "y" is shfted by one from "x".
Printing "x"and "y" gives us our "x" batch of size [4, 16] and our shifted "y" batch of size [4, 16] as can be seen below.
And that is how you get and process the data to train a GPT. This is sometimes called data wrangling. More detail about data wrangling is provided later in the chapter. Now we proceed to define the loss function. In this function we evaluate the model by predicting and comparing the predictions to the real values. The difference is the loss as can be seen below.
I will now proceed to describe the architecture of the decoder (GPT).
Architecture of the GPT or Decoder
As can be seen in the following figure, the decoder starts with inputs that go in sequentially into N (e.g. 6) decoder layers, and then a feed forward layer to predict the logit for the given token in the vocabulary. Each decoder layer has the exact same architecture and consists of multi-head attention layers, feed forward layers, and performance improvement steps such as batch normalizations, residuals, dropouts, etc. Remember that the encoder is not used for the GPT.
In the following code segment we can see the class to instantiate the whole decoder with all 6 decoder layers and the last feed forward layer.
The GPTmodel class consists of 3 functions. They are init, forward, and generate. We initialize the embedding and positional encoding object in init. The following code is what instantiates the 6 decoder layers in sequence where the outputs from one decoder layer become the inputs of another decoder layer.
The final 2 lines of code in the init function define a normalization and the feed forward layer to predict the logits (i.e. the tokens).
The second function is the forward funtion which is where we actually define the architecture from inputs to outputs through the entire deep neural network of the decoder.
First we take "idx" (the data as ids) an pass it through the embedding layer. This gives us "tok_emb". Remember that the token embedding are learned by
Transformers during the training. After that we create the positional encoding table. The encoded "tok_emb" does not go through this object.
Instead "pos_emb" is added to "tok_emb". Sequence was established when "pos_emb" was instantiated. Adding them gives us "x" which
goes into the main architecture as can be seen below
Finally, the generate function invokes the model defined through forward to generate text auto-regressively.
The GPTmodel class used a Block class to define the the decoder layers. We can now define that class. Block needs "n_embd" which is the embedding
dimension (e.g. 512), and "n_head" which is the number of Attention heads we will use (e.g. 8). We need to
calculate the "head_size" by dividing "n_embd" by "n_head". For our example this should be
64 = 512 / 8
Here it might help to look at a diagram of the decoder layer.
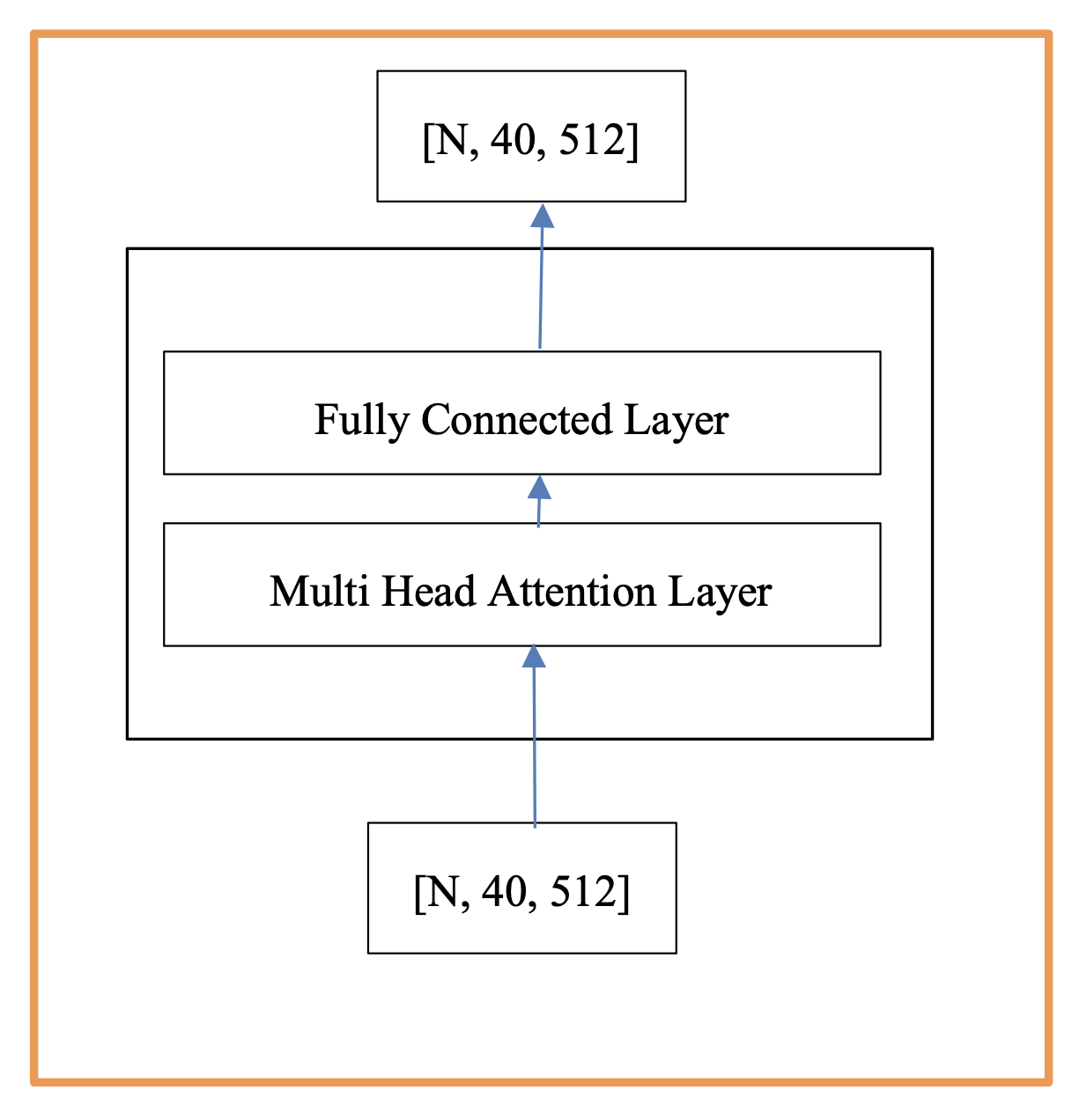
As can be seen we need a Multi-Head Attention layer followed by a FeedForward layer. Two normalizations (ln1, ln2) can also be performed.
The Block class uses 2 more classes which are Multi-Head Attention and FeedForward. We can now proceed to define these.
We can first define the Multi-Head class as follows
The Masked multi-head attention layer is done N\_head times (e.g. 8) in parallel and the results are concatenated. This concatenated result is added to the original after mapping it through one more layer and a Residual can also be used. The 2 key aspects are the instantiation of 8 heads which are parallel and independent of each other using "nn.ModuleList"as can be seen in the next code listing
and the concatenation of the 8 head Heads of size 64 to create a new tensor of size 512 ( 64 * 8 = 512).
The FeedForward class is very straight forward as can be seen below. It is a simple linear layer followed by a non-linearity.
Finally, the Multi-Head Attention class use the Head class where the Attention mechanism is defined. The next code segment is probably the most important in terms of the power of Transformers. It defines the Attention layer. Here we define the Attention Head class.
The sentence and corresponding padding mask are the only inputs to this Attention layer. The output of this Attention mechanism is then passed to a fully connected layer. The mask must not be part of the computational graph since it is only used for masking. We use the following command to keep it out of the computational graph.
The Attention mechanism uses K, Q, and V to compute the Attention scores. The values are computed from the original "x" input. The intuition is that the sentence is compared with itself and that is why the comparison or scores matrix will result in size [N_tokens, N_tokens] (e.g. [40, 40]). This is accomplished with the following code:
The input "x" is of size [N, 40, 512] and the "look_ahead_mask" is of size [N_batches, 40, 40]. Remember that using "nn.Linear" is equivalent to the following:
Once Q, K, and V are defined, the next step is to multiply Q times K. You can think of this as calculating a score of the importance of "token_i" in "x" to all other words in "x".
The variable "wei" is computed by a nn.matmul between Q and the transpose of K like so
wei = nn.matmul( Q, K, transpose_b=True)
This nn.matmul results in a matrix of size [N, 40, 40]. We then divide "wei" by
sqrt( Embd_size )
where Embd_size is equal to 64 (i.e. E ** -0.5). At this point "wei" continues to be of size [N, 40, 40].
The following code segment adds "wei" to the Mask.
An example of the effect of the mask on one sample in the batch

The "look_ahead_mask" is of size [N, 40, 40]. This should be an addition of [N, 40, 40] + [N, 40, 40]. Notice that the wei.masked_fill function
makes use on an infinity parameter. A simplified view of this operation is as follows:
wei = wei + (look_ahead_mask * -1e9)
The final part of the forward function in the Head class (next code segment) finishes the Attention computation. The softmax is used to normalize on
the last axis so that the scores add up to 1 (axis -1 is for last dimension in the tensor).
Finally, the following operation is performed which result in a tensor of size [N, 40, 64]. Remember that 8 of these Head output tensors will be concatenated to return
to the original size of [N, 40, 512] (64 * 8 = 512).
out = nn.matmul(wei, V)
The operation looks like the following [N, 40, 40] * [N, 40, 64].
So, in summary you calculate the keys, queries, and values which are tensors that map the input \textbf{x} of size [N, 40, 512] to size [N, 40, 64]. We then
calculate the scores matrix (wei) which is the Attention mechanism. This is a dot product. We matrix multiply Q with the transpose of K. This results
in a matrix that is size [N, 40, 40].
After calculating the score matrix (wei), we need to mask the values so that we don’t cheat by looking ahead. We apply the look ahead and padding masks.
The mask for look ahead attention happens before the softmax calculation. Notice that the masking is done to the dot_product scores matrix (wei) only.
The mask is multiplied with -1e9 (close to negative infinity). This is done because the mask is summed with the scaled matrix multiplication of Q and K and is
applied immediately before a softmax. The goal is to zero out padded cells, and large negative inputs to softmax are near zero in the output.
For example, the softmax ( torch.nn.softmax(a7) ) for “a” defined as follows:
a7 = torch.constant([0.6, 0.2, 0.3, 0.4, 0, 0, 0, 0, 0, 0])
gives the following
now, if some of the values are negative infinities
b7 = torch.constant([0.6, 0.2, 0.3, 0.4, -1e9, -1e9, -1e9, -1e9, -1e9, -1e9])
then the softmax operation on b7 (torch.nn.softmax(b7)) should give us
Notice the infinities are now zeros!
The decoder has a final linear layer after the 6 decoder_layer functions. The final layer in the decoder is the decoder_final_layer. This is a linear layer with
no non-linearities and a softmax that maps the tensor [N, 40, 512] to a tensor of size [N, 40, n_vocab_size].
And that covers all the classes of the NN architecture. We are now ready to instantiate the GPT and call the core functions for the optimizer, etc. like so:
The linear algebra operations that make Attention work
I have further broken down all the previous linear algebra operations using random data into the linked jupyter notebook. I recommend going through it to further understand what is going on.
Instantiate the GPT
The training function is presented below and is straight forward
Now, regenerate after some training
Using the generate function gives GPT generated text.
Obviously, the amount of data will determine the quality of a GPT and it can take a lot of money and time to properly train a GPT.
The following are examples of generated text using just single books or scripts.
For South Park training data we can get
For Harry Potter training data we can get
And that concludes the discussion on GPTs.
Encoder Only Models
The encoder has 6 sub-layers called encoder layers. Each encoding layer has a Multi-Head Attention layer followed by a standard fully connected feed forward layer. The input to the encoder goes through all these layers in the encoder and it is converted into an encoder output. The input to the encoder and the output of the encoder have the same dimensions. For instance, here, the input to the encoder would be the English sentence. The attention layer consists of 8 parallel Attention sub layers that are later concatenated. The intuition is that each of these 8 layers can learn something new and different. So this gives more capacity to the network. The input to the encoder goes through all these layers in the encoder and is converted into an encoder output. The next code segment shows the standard encoder architecture code. Notice it is almost exactly like the GPT (decoder) code. The only difference is in the last layer. The pure Encoder does not need to predict words. Instead, it takes sentences and converts them to embeddings. In this case of size [B, 40, 512].
Notice that 6 identical encoder layers are created were the outputs of one become the inputs of the next layer. The dimensions of all inputs and output at this stage are the same [B, 40, 512] where B is batch size. The input is a batch of "B" sentences, with 40 tokens per each sentence, and where 512 is each id that has been embedded to a vector of size 512. Remember that the embedding vectors of size 512 are learned by the model so initially they are random data. We use a padding mask to ignore tokens with 0 value (i.e. padding). BERTs are based on the encoder part of the original Transformer, and are encoder only Transformers.
BERT
BERT is an example of an encoder-only Transformer. In contrast to pure Encoders that take a sentence and only produce an embedding (e.g. [B, 40, 512]), BERT models will add neural network layers (called heads) after the embedding (e.g. [B, 40, 512]) to convert those embeddings into words or sentences. BERT stands for Bidirectional Encoder Representations from Transformers. They were trained using 2 approaches.
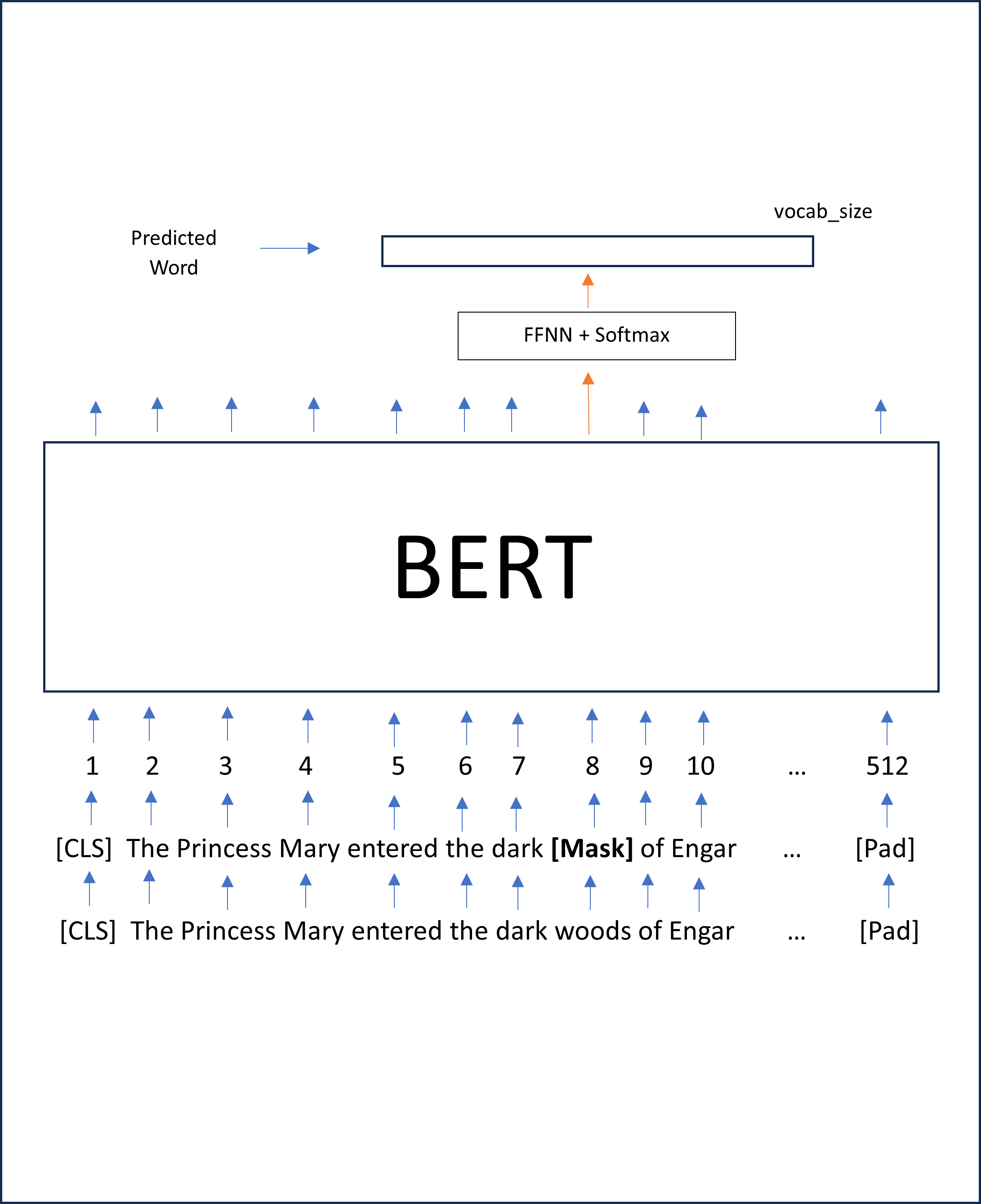
The approaches are:
- Masked language task training
- Two sentence task training
The first task BERT was pre-trained on was the Masked Language modeling approach. This approach is summarized in the previous figure. Here the BERT model receives the same sentence as input and output. Some tokens are masked and the model needs to learn to predict those masked tokens during the training process. The second task BERT was pre-trained on is a 2 sentence classification task. The figure below summarizes this approach. Basically, here, 2 sentences are given to the BERT model as input. The model trains to predict if these 2 input sentences are sequential whcih means they are also related, or if they are not sequential and, therefore, unrelated. BERT was originally developed by Google and there have now been several other versions that were developed. They all follow the simliar naming convention of being called RoBERTa, AlBERT, DistilBERT, etc.

Encoder Decoder Transformers
In this section, I will discuss the first version of the Transformer first made popular in the paper “Attention Is All You Need” by Vaswani et al.
They were first used for language translation. The Encoder Decoder with Multi Head Attention Transformer is a very deep network.
The architecture has an encoder followed by a decoder.
The decoder layer has 2 inputs. One input is the encoder output. The second input to the decoder varies based on whether you are training or predicting.
If you are training, the input to the decoder is the sentence in the other language. For instance, the Spanish sentence. In the decoder, when training the
Transformer, a mask is needed to prevent the model from seeing all the words it is trying to predict. This is called a look ahead mask.
If you are testing, the input to the decoder is just the previous words before the word you are trying to predict. You start with a start of sentence token (e.g.
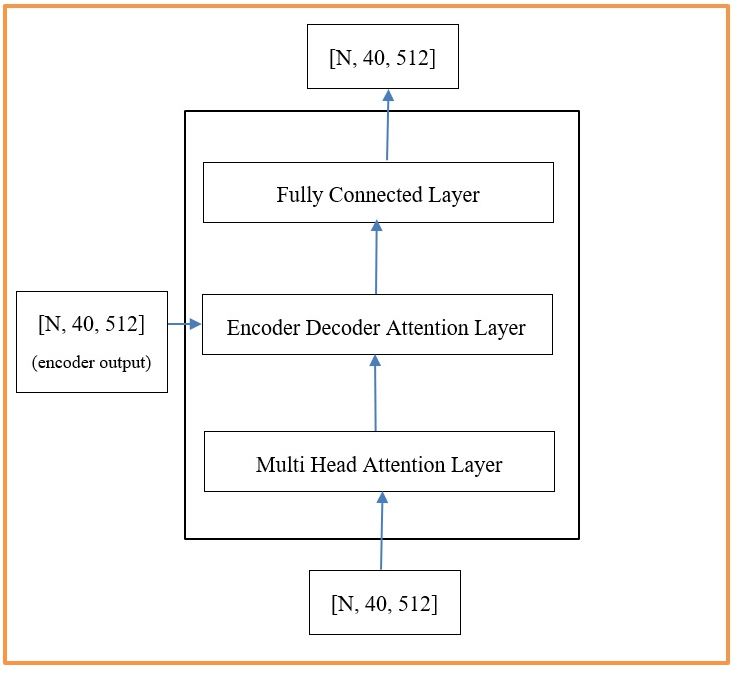
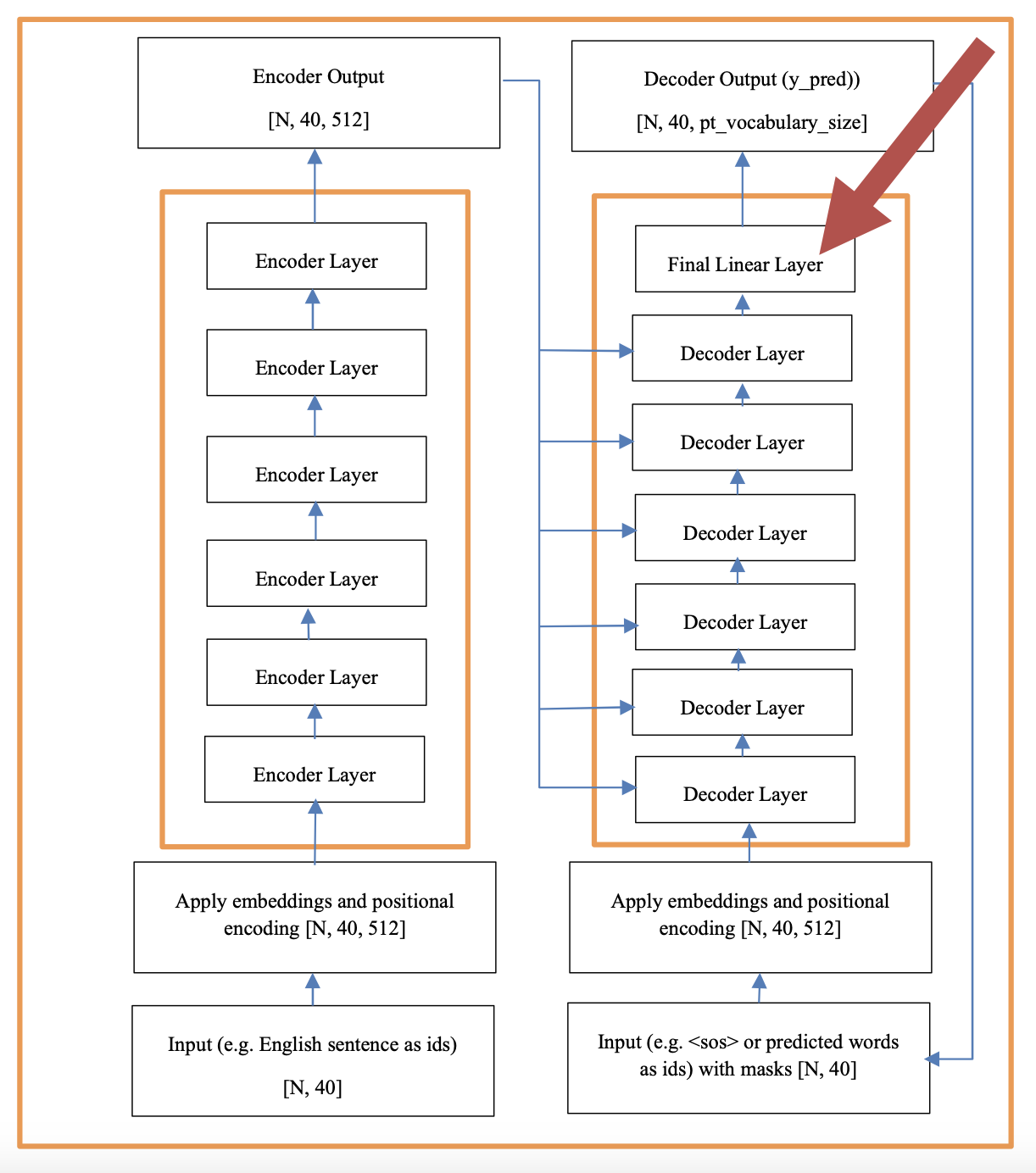
The attention layers consist of 8 parallel attention sub layers that are later concatenated. The numbers 6 and 8 are a choice the architect makes. The first code segment in this section describes the decoder’s overall architecture. The decoder has more inputs than the encoder. The decoder_layer is the busiest function of the Transformer. It is basically very similar to the encoder_layer except that it has 2 attention mechanisms instead of just one. The Multi-Head Attention is the first attention mechanism. For our reference language problem, The Portuguese sentence and corresponding padding mask are the only inputs to this sub layer. The output of this attention mechanism plus the encoder output are the inputs to the second attention mechanism which is usually referred to as the Encoder-Decoder-Attention mechanism. The output of this second Attention mechanism is passed to a fully connected layer just like the one used in the encoder. The first Masked multi-head attention layer is done 8 times in parallel just like in the encoder and the results are concatenated. This concatenated result is added to the original after mapping it through one more layer to calculate the residual. The final layer maps a tensor of size [N, 40, 512] to a tensor of size [N, 40, pt_vocab_size] where pt_vocab_size is the size of the Portuguese vocabulary. This is what allows us to select the predicted word.
Data Wrangling from Scratch
PyTorch offers many new techniques for extracting and processing data sets. As I like building things from scratch, I will present my own approach to data wrangling for Transformers. The approach is very standard and is similar to what you do in NLP for algorithms like word2vec, for instance. For this example, I will use the implementation of a Transformer-based Translator using the English to Portuguese dataset. The code and data set are available on the book GitHub. First, let us import the libraries:
I like working with python dictionaries so, for this example, I extracted the data set and created python dictionaries for training and testing. I saved the dictionaries to Python pickle files for ease of use. The following code shows how to load the dictionaries.
After loading the data sets from file, you have to create the dictionary and reverse dictionary. You create 2 dictionaries per language (e.g. two for English and two for Portuguese). These are dictionaries of ids to tokens and vice-cersa. Notice that I set the vocabulary size to 12,000. You can play with this value for optimal performance.
The following is an example function in case you want to process sentences with regular expressions or tokenize manually.
For tokenization, I used the NLTK tokenizer. In the paper “Attention Is All You Need”, the authors used byte pair encoding. Byte pair encoding does not use full words as tokens. Instead, you do something like this: "walk" and "ing" for the word “walking”. Therefore, words are broken into smaller elements (subwords). Byte-pair encoding is used to tokenize sentences in a language, which, like the WordPiece encoding, breaks words up into tokens that are slightly larger than single characters but less than entire words.
Once you have the dictionaries and the tokens, you can proceed to convert words into ids with the encode function.
Decoding is just the process in reverse. Here you convert ids back to tokens using the reverse dictionary for convenience and speed up.
The following function aligns the English and Portuguese sentence pairs and creates two lists.
The below line of code just loads the sentences data before processing from the pickle objects.
The next function creates 2 lists of aligned English and Portuguese sentences.
The function get_tokens converts each sentence into a list of tokens.
After creating the dictionaries for each language, we calculate the vocabulary size for each language.
The following “for” loop brings all the previous functions together. It results in 2 lists of sentence ids, one for each language (2 lists of Numpy objects). Notice that, to each sentence list of ids, we add the start token id at the beginning and the end token id at the end. The final “if” statement is used to only include sentences shorter than 40 tokens (the max length I used). Sentences shorter than 40 will be padded but all sentences will eventually be tensors of size 40 (n_tokens + padding).
Now we need to use a Torch padding function.
If you would like to view the data, you can do so with the following code.
After padding, the data will look like this:
And without padding, the data will look like this:
Summary
In this chapter, I have introduced the topic of Transformers. I discussed the main ideas and code for the Encoder Decoder with Multi-Head Attention Transformer first introduced by Vaswani et al. (2017), ideas of BERTs, and the GPT.