Chapter 1 - Introduction
Copyright and License
Copyright © by Ricardo A. Calix.
All rights reserved. No part of this work may be reproduced or transmitted in any form or by any means, without written permission of the copyright owner.
License: MIT.
FTC and Amazon Disclaimer
This post/page/article includes Amazon Affiliate links to products. This site receives income if you purchase through these links.
This income helps support content such as this one.

Introduction
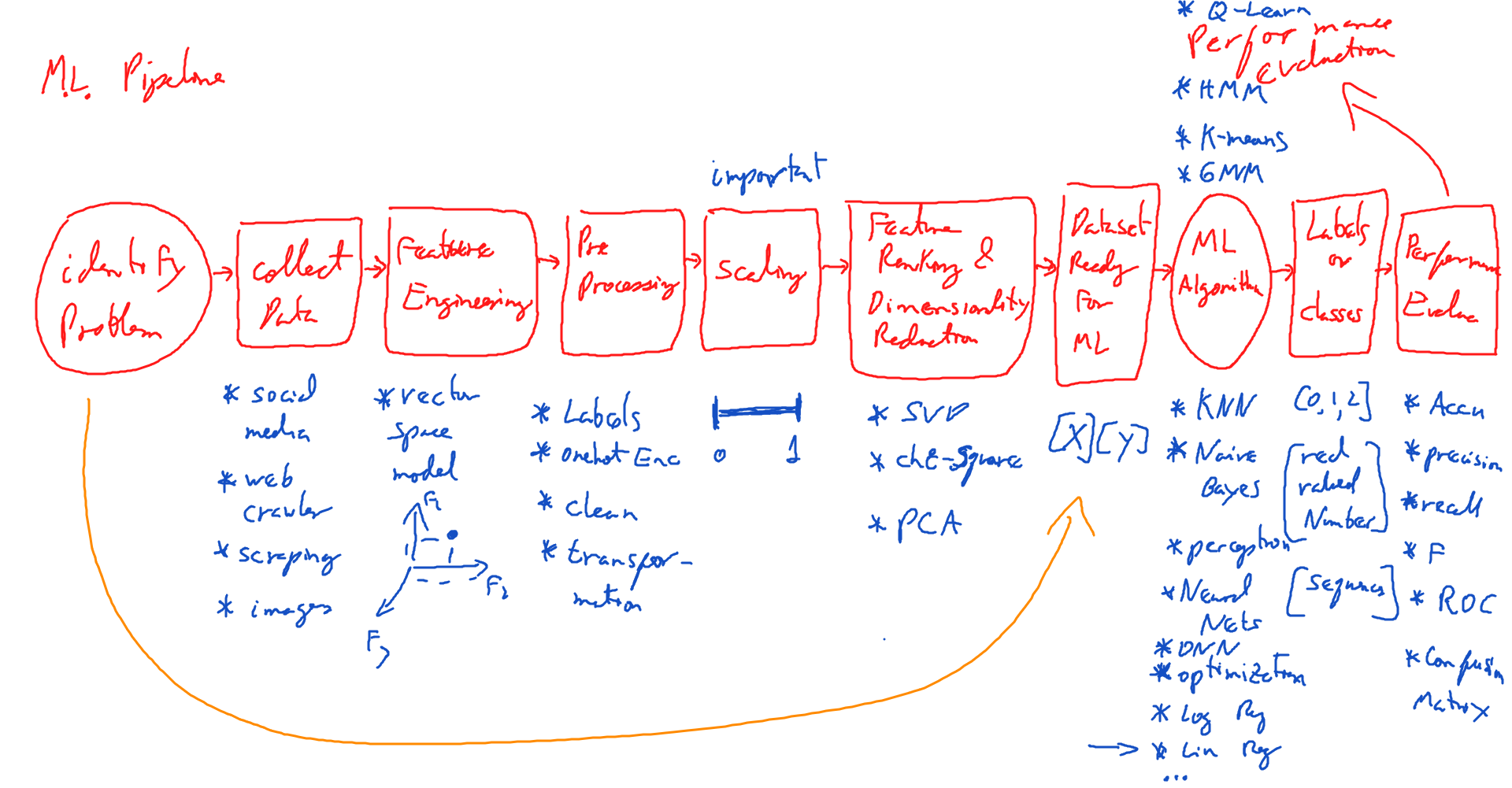
This book is very sequential and I recommend that you start from chapter 1 and read sequentially, especially if you are new to deep learning. If you are experienced in deep learning, then you can probably skip around the chapters. In this book I will discuss some aspects of the theory of deep learning while providing as much intuition as possible. I will use Linux or mac or windows, python, Sklearn, and PyTorch. Chapter 1 will briefly discuss some of the background required or recommended for deep learning. In chapter 2, I will address some of the general machine learning topics. This will be a brief review of some of the traditional (non-deep learning based) machine learning (ML) algorithms for context. I will introduce the Sklearn library to provide code examples on how to use the different ML models and other tools. I will quickly move through regression to arrive at other algorithms. There are many books on the theory of these traditional machine learning algorithms (Witten and Frank, etc.); so, instead of discussing the theory, I will concentrate on the practical aspects of using the machine learning algorithms in Python. More importantly, I will show how Sklearn can later be used with PyTorch for deep learning. Finally, I will discuss evaluation tasks and performance metrics. In chapter 3, I will address the very important issue of the data and data pre-processing. To me and most practitioners, data collection and data processing are some of the most important issues in machine learning/deep learning. There are many issues that must be addressed when dealing with data. These include: getting the data, cleaning data, pre-processing data, building a corpus and annotating it, performing inter-annotator agreement analysis, etc. Some of these issues will be discussed in chapter 3. In chapter 4, I will introduce the topic of deep learning for the first time and, in particular, how to create deep neural networks. My goal here is to help students and practitioners alike to better understand the modeling pipeline. In particular, I want the reader to be able to get data and pre-process it in the appropriate format for deep learning. This chapter also covers how to load data to your program, and how to perform simple modeling \tasks with plain vanilla deep neural networks of 2 or more hidden layers.
In the last chapters I will introduce you to the very broad topic of Transformers and the mechanism of Attention. This is one of the latest developments in deep learning as of 2017. Transformers are very powerful and offer a lot of promise for NLP. Finally, in the final chapter, I will discuss some final loose ends as well as present my final thoughts and conclusions. My goal for this book is to present intuition over equations and to use code to convey how things work. This is how I like to learn. To quote Richard Feynman: “What I cannot create, I do not understand”. Some equations can still be useful, however, so I will use them when appropriate. Additionally, all the code used in this book can be obtained from GitHub at https://github.com/rcalix1 and any other complimentary materials about the book such as some of the figures in color can be obtained from the book website at www.rcalix.com.
Setting up your Environment
In this section I will discuss how to set up your environment to get started with deep learning programming. The 2 main environments I will discuss are using Anaconda, and building the hardware with a CPU and GPU.
Anaconda
I recommend you use Anaconda. It can be installed on Linux, windows, or mac and works exceptionally well. Go to www.anaconda.org and download the software from there You will then create your anaconda environment and install most of your libraries using "pip". You can get the detailed instructions to install PyTorch from (www.PyTorch.org ) and for Sklearn from (http://scikit-learn.org/ ). To get the best out of deep learning using deep architectures and massive amounts of data you will need to use a GPU enabled machine. I suggest using the cloud or building your own GPU box.
Setting up your Environment with a Physical Box
If you want to build a physical box, I will give you some of the specifications of a machine I have used for this code. In general, the more powerful the machine the better it will be at processing large amounts of data. Here are the specifications I have used:
- A GPU GeForce RTX2080 Ti or better (H100)
- A CPU such as the AMD 12 CORE
- Power supply EVGA SuperNOVA 1600 W P2 220
- Motherboard for multiple GPU and CPU
- More than 64 GB of RAM (DDR4)
- SSD hard drive 2 TB
- A case with cooling
The total cost for 1 device with just 1 CPU and 1 GPU may be between $4,500 and $5,500. I think it is no longer feasible to build your GPU at these prices. So looking into the cloud is important. But as of today, I can still use my PC with one GPU (in 2023).
Background
So, what background should you have to get the best out of deep learning? This is a question that often comes up and it is very important. Depending on what you will do in deep learning I would recommend a course in statistics that covers probability and linear regression, programming up to data structures with python and C/C++, a course in optimization, and a course on linear algebra. Sometimes a course in computer graphics using something like openGL where you have to manipulate meshes via linear algebra operations can also be very helpful to visualize and better understand matrices and vectors. Of all of these, matrix and vector operations from linear algebra are absolutely essential for writing algorithms from scratch. The name Tensor in PyTorch means matrix of any dimension. So, even the name reminds you of the importance of linear algebra for deep learning. While this is not a linear algebra book, I will provide in the next sections a quick introduction to the topic and some useful code examples that might help you later as you progress through the different deep learning algorithms. For a better treatment of linear algebra and optimization I recommend “Linear Algebra and Optimization for Machine Learning: A Textbook” by Charu C. Aggarwal or Gilbert Strang's books.
Companion GitHub Code and YouTube videos
All companion GitHub Code and YouTube videos can be found here:
Numpy Arrays, Tensors, and Linear Algebra
In this section, I will present some of the most useful techniques used in this book, or in the deep learning field as a whole, for dealing with data. In general, we want to be very efficient in our processing of the data so we do not use python lists and “for” loops. Instead, we use Numpy arrays and tensors. These are treated as vectors and matrices in linear algebra. And more generally are referred to as tensors. The advantage of this approach is that we can perform \a lot of linear algebra based math operations like the matrix multiplication, the transpose, etc. on our data using python’s Numpy or PyTorch libraries. The best way to learn about this approach is to do a series of exercises. I will start with examples of Numpy array operations and then move to tensor operations with PyTorch. Along the way I will point out some terminology or concepts from linear algebra.
Numpy Arrays
Okay, so let’s get started. First we need to import the numpy and PyTorch libraries.
Once we import the libraries we can start writing some code. Let’s begin with some warm up examples using numpy.
To declare an array in numpy we can write
We can also declare a Numpy array with different data types. For instance, an array as float.
This gives us
A numpy matrix (2D np array) can be declared like so
This gives us a 3x3 matrix
Numpy has special functions to initialize a matrix. For example
The previous code generates a numpy array of size 10 made up of all zeros.
We can also create a matrix of all ones with the following function:
which produces a 4x6 matrix of type float
For a matrix made up of just one value we can write
This generates a 3x3 matrix where all values are 42
Sometimes we need numpy arrays with different data in them. Numpy has quick ways of creating arrays with data in them. The np.arange function is useful for this. For example
The previous code gives us a numpy array with 10 values in the range from 1 to 28 with a step of size 3.
The function linspace is another way of generating numpy arrays with data in them. Here we generate 20 data points from 0 to 1 spaced by a step size of around 0.05.
The output looks like this
Yet another useful function is np.random.random
With this function we can generate random data like the following. Here we have a 4x4 matrix with random values.
For random data with a mean of 0 and standard deviation of 1 we can write
And the data looks like this where we get a 4x4 matrix of random data with mean 0 and standard deviation 1.
Sometimes when doing linear algebra operations you need special matrices like the identity matrix. You can generate this matrix with numpy using the following code:
The previous code generates a 5x5 identity matrix like the following
Okay. So, now let’s practice generating some matrices and looking at their dimensions.
The previous code generates the following matrices with dimensions:
A matrix of size [3, 3]
A matrix of size [2, 4, 6]
Knowing how to index a Numpy array is very important. Here we have an example of how to extract values by index.
The results of the previous indexing examples are as follows:
We can also do indexing on 2D matrices as follows:
The previous indexing examples give us the following results for the given matrix
One important concept when dealing with numpy arrays or tensors is slicing. Slicing helps us to extract slices of data from a matrix like extracting 2 middle column vectors in a matrix. The following are some examples of slicing
Given a Numpy array “x” with 15 values
The previous code gives us the following slicing results
Slicing a sub matrix from a larger matrix can be done as follows
Here, from a 3x4 matrix, we get a 2x2 matrix after slicing.
That concludes are quick introduction to Numpy arrays. Now we are ready to move on to PyTorch operations on tensors.
Tensor Operations with PyTorch
In this section, we will now look at some special tensor operations and how they can be done with the PyTorch framework.
First we call the PyTorch library.
Let us begin our discussion of tensor operations with some simple examples defining tensors in PyTorch.
Our previous code creates a torch tensor of size 5 and we then the third value to 1456.0.
The function torch.argmax() is a PyTorch function that returns the index of the largest value across the axis of a tensor.
For example, in the code below we select the index for the highest values. As can be seen in the code listing answer1 is equal to 2,
and answer2 is equal to [2, 0].
Squeezing and reshaping are very important operations in PyTorch. Let us look at an example. Here, we create a dummy tensor of size [64, 1, 28, 28]
to convert it to a size [64, 28, 28] we can use the \textbf{torch.squeeze} function as follows
Now we will proceed to reshape the part of the tensor that is 28x28 into just one dimension equal to 784. We can do that witht the follwing code which will return a tensor of size [64, 784]
Conclusion
This concludes chapter 1. In it, I described a lot of the background on the tools and the development environment needed, as well as many math operations with tensors.