Chapter 9 - Reinforcement Learning
In this section of the book I will cover the topic of Reinforcement Learning. This is an area of machine learning somewhere between supervised learning and unsupervised learning. It has been extensively applied to recommender systems and AI-based games. Recently, it was shown that a deep Q-network, using only pixels and game scores as inputs, could achieve a playing level comparable to that of professional human gamers across a set of 49 Atari games (\babelEN{\cite{mnihRef}}). The main advantage of applying reinforcement learning to games is that games are governed by rules. You have game states (the inputs) and actions (output) that lead to new states and rewards (the objectives to maximize). Because of this, no annotation is needed and instead you rely on the rules of the game for feedback (e.g. instead of annotated labels).
Copyright and License
All rights reserved. No part of this work may be reproduced or transmitted in any form or by any means, without written permission of the copyright owner.
MIT License.
FTC and Amazon Disclaimer
This post/page/article includes Amazon Affiliate links to products. This site receives income if you purchase through these links.
This income helps support content such as this one.

Reinforcement Learning
In this section of the book I will cover the topic of Reinforcement Learning. This is an area of machine learning somewhere between supervised learning and unsupervised learning. It has been extensively applied to recommender systems and AI-based games. Recently, it was shown that a deep Q-network, using only pixels and game scores as inputs, could achieve a playing level comparable to that of professional human gamers across a set of 49 Atari games (\babelEN{\cite{mnihRef}}). The main advantage of applying reinforcement learning to games is that games are governed by rules. You have game states (the inputs) and actions (output) that lead to new states and rewards (the objectives to maximize). Because of this, no annotation is needed and instead you rely on the rules of the game for feedback (e.g. instead of annotated labels). There are several types of reinforcement learning techniques. In this chapter, I will focus on getting started with Q-learning since this is the technique used in the Mnih et al (2015) paper I referenced above. Here, I will try to provide a simple intuition based description of the technique. I should note that to achieve the level of Q-Learning presented in the Mnih et al (2015) paper, several additional optimizations need to be included. However, the discussion in this chapter should provide a simple way to get started with Q-Learning.
So what is Q-Learning?
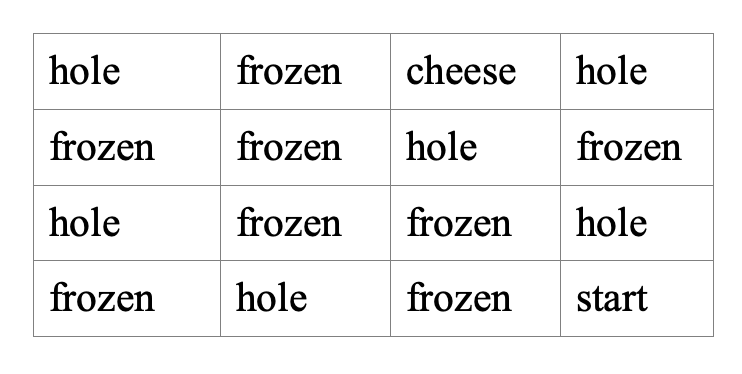
Q-Learning tries to learn the value of being in a given state (s), and taking a specific action from there. As I indicated, Q-learn has been applied to games. The best way to understand the algorithm is to analyze it from the point of view of a game. Here we will use Python’s OpenAI Gym module to play games. We will select the simple FrozenLake game environment. FrozenLake is a game about crossing a frozen lake that has some cracks in the ice with holes and there is wind sometimes that pushes the person crossing it. The game is very simple and consists of a grid that is 4x4 like so.
So, the objective is to get to the cheese without falling into a hole or being pushed by the wind into a hole. There are 4 moves which are up, down, right, and left. There is only one reward and that is to get to the cheese. However, you only get that reward in the future by first taking several steps on frozen blocks without falling in a hole. Therefore, one challenge is that you have to state your objective in terms of several future moves. This is accomplished using something called the Bellman Equation. The key to predicting these rewards is to know the associated reward given a current state and action to take. This is called a Q mapping
Q (state, action) = reward
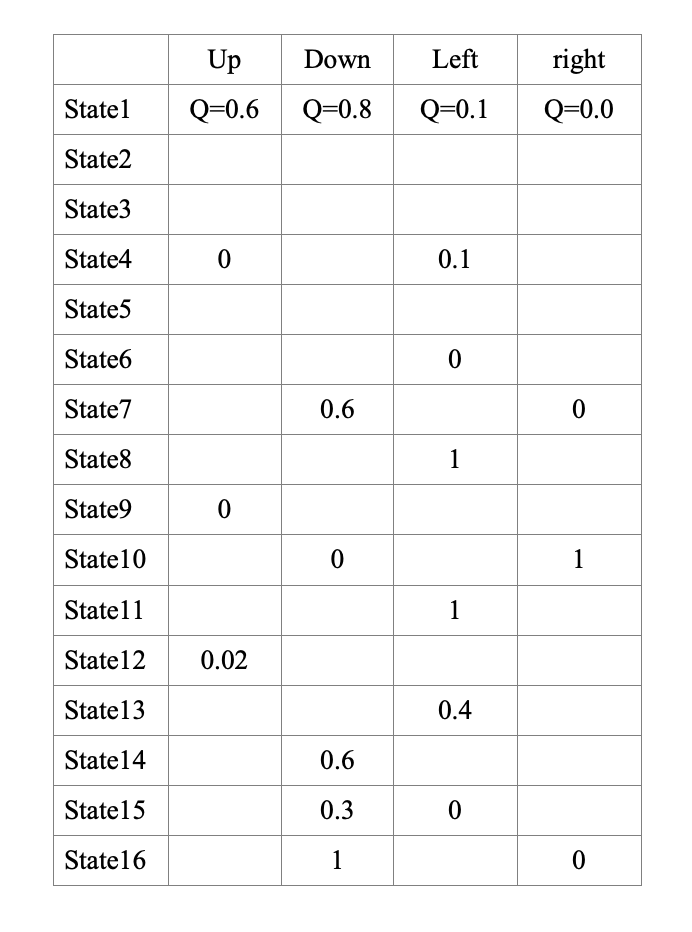
For such a simple grid, we could just use a table. In this case our table would be 16x4 because there are 16 possible states (position in the grid of 4x4) and there are 4 actions (up, down, right, left). Since we know the rules of the game and the layout of the grid, we can populate the table and learn the Q rewards for each state/action pair. An example of the table can be seen below.
Now the main challenge is that we need to learn future rewards for future actions as we move through the grid. Here the Bellman equation will help. Think of the Bellman equation as a type of recursive equation that looks at the future state given a current state. The Bellman equation is as follows:
These values can be looked up from the Table. The code discussed here can be downloaded from the course website or the github repository. In the next section, the python Q-learning code will be discussed which only uses a table to determine the rewards and the path to follow. Future sections will use the same algorithm but will replace the use of the table with a neural network so that we can see how deep neural networks can improve the approach.
Q-Learning using a Table
In this section we discuss the code to implement Q-Learning using a table. This code makes use of the OpenAI gym library. The libraries used can be seen in the next code segment.
The frozenLake game can be initialized by creating the env object as can be seen below. This object represents the game and holds all the parameters related to states, actions, rewards, and current game state.
The next step is to initialize the table $ Q $ to all zeros and of size 16x4. Here env.observation\_space.n = 16 and env.action\_space.n = 4.
We take 2000 epochs (or episodes) and initialize some parameters lr and y. Each episode represents a game played. We use \textbf{jList} and \textbf{rList} to collect the number of steps taken per episode and the total reward per episode, respectively. These are used to collect results of each game.
The following code segment goes over the main loop of the Q-learn algorithm.
In the next code segment, the line
indicates that we are going to play num\_episodes = 2000 games. During these 2000 tries we will learn the best path to take. From the main loop we can see that the line
restarts the game for every episode so we can play it again and assign the initial state to \textbf{s}. The variable \textbf{rAll} adds up the accumulated rewards for this episode. The variables \textbf{d} and \textbf{j} are control variables to indicate if the game has ended and to count the number of steps taken. The code in the while loop is what allows the algorithm to learn or update the values in the \textbf{Q} table designated by the variable \textbf{Q}. To take the first step we need to pick an action to follow. We do this with the following lines of code:
and
The variable \textbf{zz} is the size \textbf{n} of all actions in the game (up, down, left, right) which in this case is 4. The statement Q[s, :] selects the current Q values (rewards) associated with state \textbf{s}. The statement
adds randomness to the four Q values for the current state. Basically, you randomly increment the Q values for the current state and then select the highest one with
by selecting the highest Q value you determine what action (a) you take given the current state. Once the action "a" is selected, we can proceed to evaluate it in the game to obtain our new state (position) and the reward (did we fall in a hole or advanced to a frozen block). We do this with
here, "s1" is the new state (position) and \textbf{r} is the reward. The parameter \textbf{d} indicates end of the game. Given this new information about the result of our action, we can proceed to update the Q-table with our new results and new knowledge about the state of the game. This is done with the statement
In this statement, \textbf{Q[s, a]} contains the current Q value (reward) associated with the state \textbf{s} and the action \textbf{a}. This is the Bellman equation which can be viewed as
Q[s,a] = Q[s,a] + next_s_Q
The term next_s_Q contains the current reward for state \textbf{s} plus the maximum reward for the next state \textbf{s1}. The parameters \textbf{lr} and \textbf{y} are weights to control the importance of the next state’s reward when updating the current states reward (Q value). We can think of this parameter
as a regularization parameter. At this point we are almost done and we can proceed to accumulate our results. The statement
accumulates the total rewards. The statement
assigns the current state \textbf{s1} to \textbf{s}. The "if" statement in the folowing code listing
ends the game if \textbf{d} indicates end of game. The statement
accumulates the number of steps taken to reach end of game. The statement
appends rewards per game to a list so that they can be viewed later. That is it. We have finished our discussion of Q-learn with tables on the frozenLake game. Now we can proceed to replace the table with a neural network.
Q-Learning using a Neural Network
Now that we understand the frozenLake game with a table, we can proceed to replace the table with a neural network.
It is important to note here that the weights matrix \textbf{W} in the neural network can be thought of as representing the \textbf{Q} table.
Otherwise, just think of the whole neural network as the table. We give it the states vector (size=16) as input and the network predicts the actions
vector (size=4) per state.
Let us begin.
First we include the libraries as can be seen below. Notice we now add PyTorch.
We create the game with the env object.
Next, we define our familiar neural network classes and functions for the loss and training. The first Q NN class creates a simple logistic regression type neural network. Here, the \textbf{W} replaces the \textbf{Q} table. Notice the dimensions of \textbf{W} are 16x4 because we have 16 states in the game and 4 actions. The \textbf{Qout} tensor (our predicted \textbf{y} in previous chapters) is the result of a matmul operation between \textbf{x} (our states) and \textbf{W} (the weights or Q values in this case).
With
we get the actions vector. We will use a torch.max function later to select the action. As can be seen from the previous class code, the network looks like the figure below.
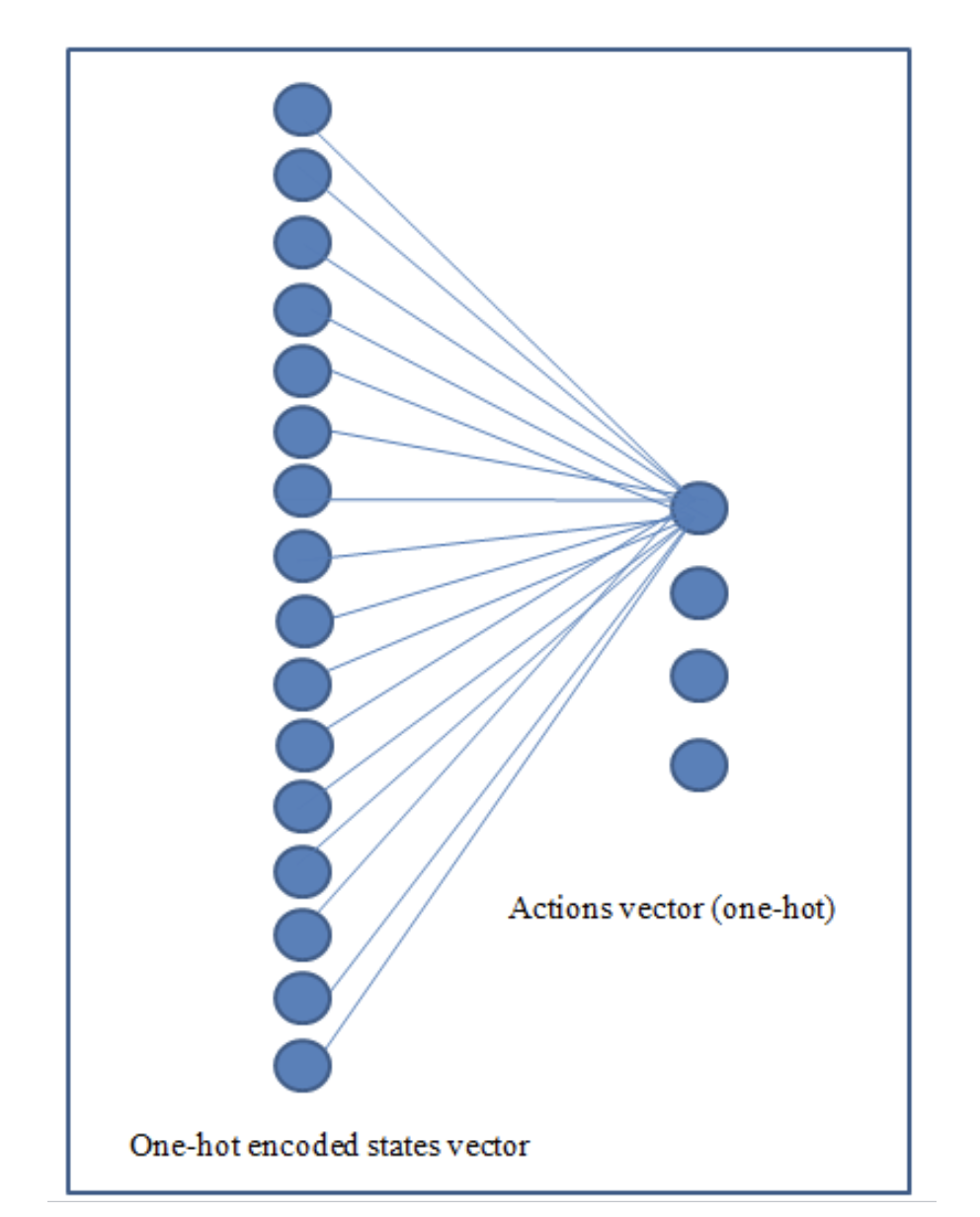
It is important to note that this is a basic architecture and that much more complex deep architectures with different activation functions could be used such as architectures with many hidden layers or convolutional neural networks, etc. I was able to achieve good results using the following MLP neural network architecture.
Notice that the NN classes us the following function called \textbf{gen\_state\_vector(s)}. We will use this function to convert state in integer form into one hot encoded vectors of size 16.
The function
takes the current state in the variable \textbf{s} and converts it into a one-hot encoded representation. For instance, if the current state is 4, then the one-hot encoded representation (of size 16) looks like this
The loss function can be Least Squares Estimation which is the same as for regression! To calculate the error, we basically compare \textbf{q_pred} to \textbf{target_q} and try to minimize the error.
We can set the following parameters. We create lists to contain steps taken per episode (game) and rewards per game.
The optimization is nothing more than the very familiar Gradient Descent (Adam) with a learning rate of 0.001. We instantiate the Q NN MLP model.
Finally, we are ready for the main loop which is shown in the next code segment below.
I will now proceed to break the main loop into parts to make it easier to describe. As can be seen in the code segment below, we run the main loop 4000 times (\textbf{num_episodes}) which means that we play 4000 games. Each time we play a game, we reinitialize the board ( s = env.reset() ) and initialize the rewards variable (\textbf{rAll}) to zero. The variable \textbf{j} is the counter for the current step and \textbf{d} is used to determine if the game is over (win or loss).
for every game iteration we run the following while loop. This while loop is the main code that helps us to learn the \textbf{Q} values and traverse the board (e.g. play the frozen lake game).
We perform 1000 steps since it should not take more than 1000 steps to traverse the frozen lake. If it does, the game should end. The line in the while loop is used to increment the steps
After incrementing the steps, we proceed to perform our first model run to train the PyTorch model. Here we predict an action and get Q_s from the model.
The next step is to take the predicted action in \textbf{“a”} and run it through the game. The below statement runs the action through env.step() and this function returns the new state \textbf{s1} which is the new position in the frozen lake grid, \textbf{r} is the reward associated with the step \textbf{s} (for instance r = 0.43) , and \textbf{d} indicates if the game is over (found the cheese or fell in the frozen lake). You know you have lost the game if \textbf{d} is True and if the reward is zero at the same time. To help the model learn, we can assign negative rewards every time that happens. Knowing when to assign rewards is very challenging in Reinforcement Learning. Here, frozen lake is a simple game and using this type of approach is possible. Current research proposes to replace the rewards heuristics with neural networks. One current effective approach is called RLHF which stands for reinforcement learning through human feed-backs.
With the new state \textbf{s1}, we proceed to run the PyTorch model again. Here we run the model again using \textbf{s1}.
So \textbf{Q\_s1} will now contain the 4 neuron vector with the \textbf{Q} values for all 4 actions given state \textbf{s1}. We grab the max
value from \textbf{Q\_s1} (not the index) and use that to calculate \textbf{target\_q} using the Bellman equation.
Recall that the Bellman equation looks like this:
Interestingly, only one of the 4 values in \textbf{Q\_s1} is updated using the Bellman equation. The other values remain the same. The dimension of \textbf{target\_q} is only one which means that that is the only value we will use to perform the optimization. Finally, we do a final update of the PyTorch model by calculating the losses on state \textbf{“s”} and action \textbf{a}.
Finally, the last peace of code adds up the rewards, assigns the new state \textbf{s1} to \textbf{s}, and checks to see if the game is over.
Once you exit the while loop, the last part is to append the results of the current game to the results lists.
Well, that is it for the algorithm discussion. Finally, we print our results and plot them.
That is it. We have completed implementing our Q learning algorithm with a neural network. In the next section we will add a simple improvement to the code that will improve performance.
Performance, Q-NN, and randomness
In the previous section we described the code to implement Q-learning with a neural network on the frozen lake game. That was the simplest implementation of it.
To improve the results, we can add a few lines of additional code which will allow the algorithm to better converge and learn better Q-values. The additions
are simple and basically relate to adding randomness to the code. The full version of the code can be seen below. I will additionally discuss how to measure
performance with RL.
The new lines of code add randomness to the selection of the next action to take. The idea is that at the beginning of the learning process, the action prediction
function may not be very good. Therefore, picking an action randomly at the beginning may be better than picking actions with the model.
This is reflected in the code segment below.
A random number is obtained and compared to \textbf{epsilon}. If less than \textbf{epsilon}, the action is selected randomly.
As the algorithm improves and the Q values are better, the value of \textbf{epsilon} can be adjusted so that action is more often selected with the
model and not with the random function.
The code can be seen here where the value of \textbf{“epsilon”} is adjusted.
That is all it takes to implement randomness. Now we are ready to measure the performance of the RL model using frozen lake. After training,
we can perform several calculations to measure performance.
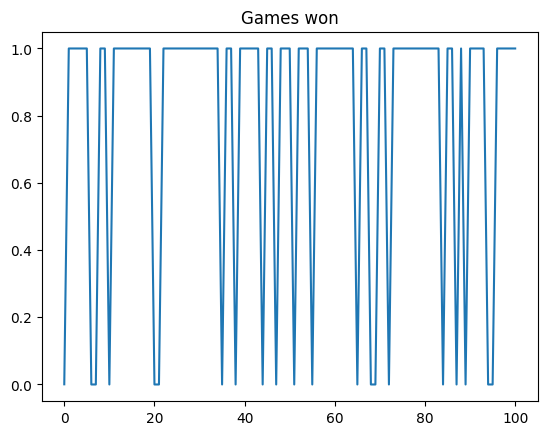
First let us count the number of successes during the last 100 training games (out of 4000). The following calculation gives us a score of 75\%.
We can look at the rewards trend with the following code.
During training, we collected the total reward per each of the 4000 games. Visualising all 4000 rewards can be confusing. However, if we average every 100 rewards in sequence, we can clearly see that the rewards are going up. One of the goals in RL is for the model to increase its rewards.
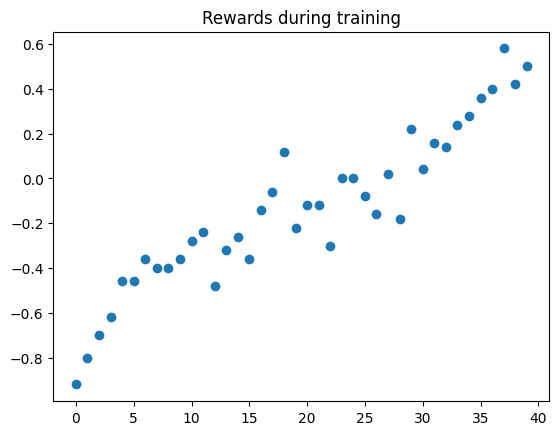
Once the model is trained, we want to run it again without training to test its performance. This can be accomplished with the following code
After running the evaluation (no training), the model is able to win 79\% of the games it played.
Summary
In this chapter we have discussed the Q learning algorithm as part of the larger topic of Reinforcement Learning using tables and neural networks with randomization.